Set up your localization attribute
Before you can set up multi-language messages, you need to store your audience’s language preferences as an attribute. You can tell us what that attribute is, and then use it to send people messages in their preferred language!
How it works
Before you can send localized messages, you need to go to Workspace Settings > Language settings and tell us what attributeA key-value pair that you associate with a person or an object—like a person’s name, the date they were created in your workspace, or a company’s billing date etc. Use attributes to target people and personalize messages. Attributes are analogous to traits in Data Pipelines. stores your audience’s language preferences. This attribute must store values we support, meaning they’re either:
- a two letter language code, like
enfor English - a four-letter language and region code, separated by a dash, like
en-USfor English speakers in the United States.
We’ll match your customers’ attribute values to the corresponding languages for your message. If a person’s language attribute doesn’t match one of the languages in your message, they’ll receive the Default message.
message] --> D{Does a person's language
attribute match a message?} D -->|no| H[Person gets
Default message] D -->|yes, lang=es| E[Person gets
Spanish message] D -->|yes, lang=fr| F[Person gets
French message] D -->|yes, lang=de| G[Person gets
German message]
If you already store languages in a format that doesn’t fit our standards, you may be able to convert your current value(s) with liquidA syntax that supports variables, letting you personalize messages for your audience. For example, if you want to reference a person’s first name, you might use the variable {{customer.first_name}}. or JavaScript.
Set your language attribute
When you add a language attribute, we assume that values fit our list of supported languages. If you already have a “language attribute”, but it doesn’t use our supported values, you may want to create a new attribute and set up a campaign to convert your existing attribute to our supported formats.
Before you can send localized messages, you need to go to Workspace Settings > Language settings and tell us what attributeA key-value pair that you associate with a person or an object—like a person’s name, the date they were created in your workspace, or a company’s billing date etc. Use attributes to target people and personalize messages. Attributes are analogous to traits in Data Pipelines. stores your audience’s language preferences. This attribute must store values we support, meaning they’re either:
- a two letter language code, like
enfor English - a four-letter language and region code, separated by a dash, like
en-USfor English speakers in the United States.
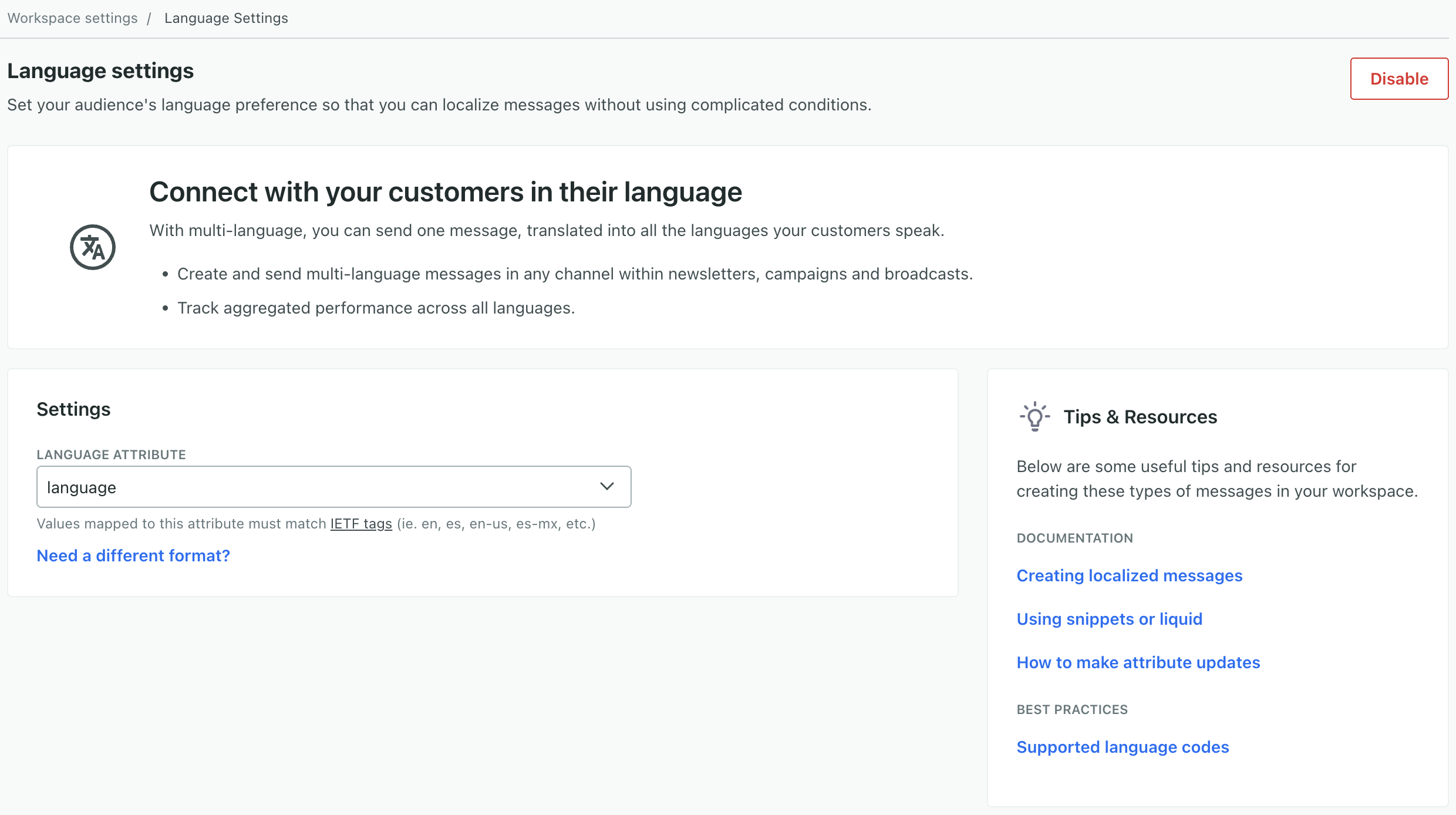
To set your workspace’s language attribute:
- Go to Settings > Workspace Settings.
- Find Language Settings and click Get Started.
- Enter the name of the attribute representing your audience’s language.
Convert language attributes to our standards
If you already store your audience’s language preference in a format that doesn’t fit ISO-3166-1 (alpha 2) or IETF standards, you can set up a campaign to reformat your language attribute.
Create a new attribute to store the reformatted preference, in case integrations continue to add or update people with a language preference that you need to reformat.
- Create a segmentA group of people who match a series of conditions. People enter and exit the segment automatically when they match or stop matching conditions. containing people with your original language attribute.
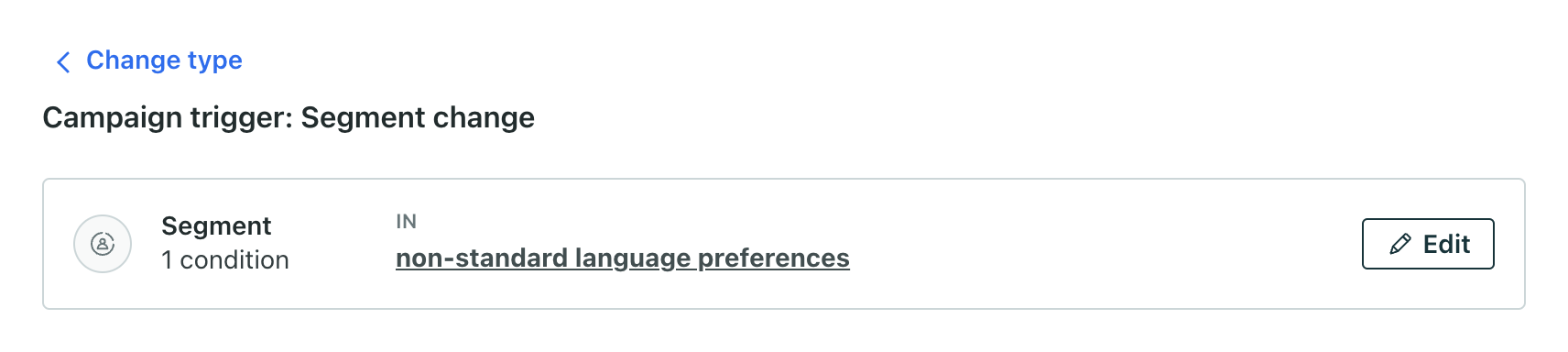
- Create a campaign. Click “Segment change” as the trigger type. On the Trigger page:
- Click Choose segment.
- Choose the segment you just created from the dropdown.
- Click Save condition.
- Click Save & Next.
- In your Workflow, drag Create or update person onto the canvas.
- Give the action a Name, and click Add Details.
- Under attribute, type the name of the language attribute you set in Language settings.
- Select Liquid or JavaScript, and write an expression to convert or map languages. We’ve provided some examples below.

- Under Sample Data, click next to the original attribute.
- Set the value to Remove attribute. This removes the original language attribute and removes the person from the segment you set up in the first step.
Use liquid to convert language values
When you use the Create or Update Person action, you can set and modify attributes using liquidA syntax that supports variables, letting you personalize messages for your audience. For example, if you want to reference a person’s first name, you might use the variable {{customer.first_name}}.. The liquid expression you use to map your old language attribute to your new one depends on your current language format, but we’ve provided some ideas below.
If you store languages with an underscore instead of a dash (e.g. en_US instead of en-US), you can replace the underscore easily with replace:
// assume input en_us
{{ customer.language | replace: "_", "-" }}
// outputs en-us
If you store languages without a delimiter, you can add one by slicing your original language attribute:
// assume input enUS
{{ customer.language | slice: 2 }}-{{customer.language | slice: 3, 2}}
// output
Or, if you store languages as full names, you may need to map some of them. You can do this with condtitions:
// assume languages are english, french, and german
{% if customer.language == "German" %}
de
// output for german
{% else %}
{{customer.language | slice: 2, 2}}
// for french and english, use the first two letters of language code
{% end %}
Use JavaScript to convert language values
When you use the Create or Update Person action, you can set and modify attributes using JavaScript. The liquid expression you use to map your old language attribute to your new one depends on your current language format, but we’ve provided some ideas below.
If you store languages with an underscore instead of a dash (e.g. en_US instead of en-US), you can replace the underscore easily with replace:
// assume `language` attribute formatted en_us
return customer.language.replace("_", "-");
// outputs en-us
If you store languages without a delimiter, you can add one by slicing your original language attribute:
// assume `language` attribute formatted enUS
return customer.language.slice(0, 2) + "-" + customer.language.slice(2);
// output
Or, if you store languages as full names, you may need to map some of them. You can do this with condtitions:
// assume languages are english, french, and german
if (customer.language == "German") {
return de;
// output for german
} else {
customer.language.slice(0, 2);
// for french and english, use the first two letters of language code
}
Supported languages and locales
You must format the values of your language attribute as two-letter language codes with an optional two-letter region code separated by a dash, like en or en-US.
Language attributes are not case sensitive, but language-region codes must be separated by a dash. For example, both es-MX and es-mx represent Spanish formatted for speakers in Mexico.
These codes come from the ISO-3166-1 (alpha 2) and IETF standards respectively. If you’re looking for a language or locale that we don’t support, let us know!
| Language/Locale | Code |
| Afrikaans | af |
| Afrikaans (South Africa) | af-ZA |
| Amharic (Ethiopia) | am-ET |
| Arabic | ar |
| Arabic (U.A.E.) | ar-AE |
| Arabic (Bahrain) | ar-BH |
| Arabic (Algeria) | ar-DZ |
| Arabic (Egypt) | ar-EG |
| Arabic (Iraq) | ar-IQ |
| Arabic (Jordan) | ar-JO |
| Arabic (Kuwait) | ar-KW |
| Arabic (Lebanon) | ar-LB |
| Arabic (Libya) | ar-LY |
| Arabic (Morocco) | ar-MA |
| Arabic (Oman) | ar-OM |
| Arabic (Qatar) | ar-QA |
| Arabic (Saudi Arabia) | ar-SA |
| Arabic (Syria) | ar-SY |
| Arabic (Tunisia) | ar-TN |
| Arabic (Yemen) | ar-YE |
| Mapudungun (Chile) | arn-CL |
| Assamese (India) | as-IN |
| Azeri | az |
| Azeri (Cyrillic) (Azerbaijan) | az-Cyrl-AZ |
| Azeri (Latin) (Azerbaijan) | az-Latn-AZ |
| Bashkir (Russia) | ba-RU |
| Belarusian | be |
| Belarusian (Belarus) | be-BY |
| Bulgarian | bg |
| Bulgarian (Bulgaria) | bg-BG |
| Bengali (Bangladesh) | bn-BD |
| Bengali (India) | bn-IN |
| Tibetan (People's Republic of China) | bo-CN |
| Breton (France) | br-FR |
| Bosnian (Cyrillic) (Bosnia and Herzegovina) | bs-Cyrl-BA |
| Bosnian (Latin) (Bosnia and Herzegovina) | bs-Latn-BA |
| Catalan | ca |
| Catalan (Catalan) | ca-ES |
| Corsican (France) | co-FR |
| Czech | cs |
| Czech (Czech Republic) | cs-CZ |
| Welsh (United Kingdom) | cy-GB |
| Danish | da |
| Danish (Denmark) | da-DK |
| German | de |
| German (Austria) | de-AT |
| German (Switzerland) | de-CH |
| German (Germany) | de-DE |
| German (Liechtenstein) | de-LI |
| German (Luxembourg) | de-LU |
| Lower Sorbian (Germany) | dsb-DE |
| Divehi | dv |
| Divehi (Maldives) | dv-MV |
| Greek | el |
| Greek (Greece) | el-GR |
| English | en |
| English (Caribbean) | en-029 |
| English (Australia) | en-AU |
| English (Belize) | en-BZ |
| English (Canada) | en-CA |
| English (United Kingdom) | en-GB |
| English (Ireland) | en-IE |
| English (India) | en-IN |
| English (Jamaica) | en-JM |
| English (Malaysia) | en-MY |
| English (New Zealand) | en-NZ |
| English (Republic of the Philippines) | en-PH |
| English (Singapore) | en-SG |
| English (Trinidad and Tobago) | en-TT |
| English (United States) | en-US |
| English (South Africa) | en-ZA |
| English (Zimbabwe) | en-ZW |
| Spanish | es |
| Spanish (Argentina) | es-AR |
| Spanish (Bolivia) | es-BO |
| Spanish (Chile) | es-CL |
| Spanish (Colombia) | es-CO |
| Spanish (Costa Rica) | es-CR |
| Spanish (Dominican Republic) | es-DO |
| Spanish (Ecuador) | es-EC |
| Spanish (Spain) | es-ES |
| Spanish (Guatemala) | es-GT |
| Spanish (Honduras) | es-HN |
| Spanish (Latin America) | es-LA |
| Spanish (Mexico) | es-MX |
| Spanish (Nicaragua) | es-NI |
| Spanish (Panama) | es-PA |
| Spanish (Peru) | es-PE |
| Spanish (Puerto Rico) | es-PR |
| Spanish (Paraguay) | es-PY |
| Spanish (El Salvador) | es-SV |
| Spanish (United States) | es-US |
| Spanish (Uruguay) | es-UY |
| Spanish (Venezuela) | es-VE |
| Estonian | et |
| Estonian (Estonia) | et-EE |
| Basque | eu |
| Basque (Basque) | eu-ES |
| Persian | fa |
| Persian (Iran) | fa-IR |
| Finnish | fi |
| Finnish (Finland) | fi-FI |
| Filipino (Philippines) | fil-PH |
| Faroese | fo |
| Faroese (Faroe Islands) | fo-FO |
| French | fr |
| French (Belgium) | fr-BE |
| French (Canada) | fr-CA |
| French (Switzerland) | fr-CH |
| French (France) | fr-FR |
| French (Luxembourg) | fr-LU |
| French (Principality of Monaco) | fr-MC |
| Frisian (Netherlands) | fy-NL |
| Irish (Ireland) | ga-IE |
| Scottish Gaelic (United Kingdom) | gd-GB |
| Galician | gl |
| Galician (Galician) | gl-ES |
| Alsatian (France) | gsw-FR |
| Gujarati | gu |
| Gujarati (India) | gu-IN |
| Hausa (Latin) (Nigeria) | ha-Latn-NG |
| Hebrew | he |
| Hebrew (Israel) | he-IL |
| Hindi | hi |
| Hindi (India) | hi-IN |
| Croatian | hr |
| Croatian (Latin) (Bosnia and Herzegovina) | hr-BA |
| Croatian (Croatia) | hr-HR |
| Upper Sorbian (Germany) | hsb-DE |
| Hungarian | hu |
| Hungarian (Hungary) | hu-HU |
| Armenian | hy |
| Armenian (Armenia) | hy-AM |
| Indonesian | id |
| Indonesian (Indonesia) | id-ID |
| Igbo (Nigeria) | ig-NG |
| Yi (People's Republic of China) | ii-CN |
| Icelandic | is |
| Icelandic (Iceland) | is-IS |
| Italian | it |
| Italian (Switzerland) | it-CH |
| Italian (Italy) | it-IT |
| Inuktitut (Syllabics) (Canada) | iu-Cans-CA |
| Inuktitut (Latin) (Canada) | iu-Latn-CA |
| Japanese | ja |
| Japanese (Japan) | ja-JP |
| Georgian | ka |
| Georgian (Georgia) | ka-GE |
| Kazakh | kk |
| Kazakh (Kazakhstan) | kk-KZ |
| Greenlandic (Greenland) | kl-GL |
| Khmer (Cambodia) | km-KH |
| Kannada | kn |
| Kannada (India) | kn-IN |
| Korean | ko |
| Korean (Korea) | ko-KR |
| Konkani | kok |
| Konkani (India) | kok-IN |
| Kyrgyz | ky |
| Kyrgyz (Kyrgyzstan) | ky-KG |
| Latin | la |
| Luxembourgish (Luxembourg) | lb-LU |
| Lao (Lao P.D.R.) | lo-LA |
| Lithuanian | lt |
| Lithuanian (Lithuania) | lt-LT |
| Latvian | lv |
| Latvian (Latvia) | lv-LV |
| Maori (New Zealand) | mi-NZ |
| Macedonian | mk |
| Macedonian (Former Yugoslav Republic of Macedonia) | mk-MK |
| Malayalam (India) | ml-IN |
| Mongolian | mn |
| Mongolian (Cyrillic) (Mongolia) | mn-MN |
| Mongolian (Traditional Mongolian) (People's Republic of China) | mn-Mong-CN |
| Mohawk (Canada) | moh-CA |
| Marathi | mr |
| Marathi (India) | mr-IN |
| Malay | ms |
| Malay (Brunei Darussalam) | ms-BN |
| Malay (Malaysia) | ms-MY |
| Maltese (Malta) | mt-MT |
| "Norwegian (Bokmål)" | nb |
| "Norwegian, Bokmål (Norway)" | nb-NO |
| Nepali (Nepal) | ne-NP |
| Dutch | nl |
| Dutch (Belgium) | nl-BE |
| Dutch (Netherlands) | nl-NL |
| "Norwegian, Nynorsk (Norway)" | nn-NO |
| Norwegian | no |
| Sesotho sa Leboa (South Africa) | nso-ZA |
| Occitan (France) | oc-FR |
| Oriya (India) | or-IN |
| Punjabi | pa |
| Punjabi (India) | pa-IN |
| Polish | pl |
| Polish (Poland) | pl-PL |
| Dari (Afghanistan) | prs-AF |
| Pashto (Afghanistan) | ps-AF |
| Portuguese | pt |
| Portuguese (Brazil) | pt-BR |
| Portuguese (Portugal) | pt-PT |
| K'iche (Guatemala) | qut-GT |
| Quechua (Bolivia) | quz-BO |
| Quechua (Ecuador) | quz-EC |
| Quechua (Peru) | quz-PE |
| Romansh (Switzerland) | rm-CH |
| Romanian | ro |
| Romanian (Romania) | ro-RO |
| Russian | ru |
| Russian (Russia) | ru-RU |
| Kinyarwanda (Rwanda) | rw-RW |
| Sanskrit | sa |
| Sanskrit (India) | sa-IN |
| Yakut (Russia) | sah-RU |
| Sami (Northern) | se |
| Sami (Northern) (Finland) | se-FI |
| Sami (Northern) (Norway) | se-NO |
| Sami (Northern) (Sweden) | se-SE |
| Sinhala (Sri Lanka) | si-LK |
| Slovak | sk |
| Slovak (Slovakia) | sk-SK |
| Slovenian | sl |
| Slovenian (Slovenia) | sl-SI |
| Sami (Southern) (Norway) | sma-NO |
| Sami (Southern) (Sweden) | sma-SE |
| Sami (Lule) (Norway) | smj-NO |
| Sami (Lule) (Sweden) | smj-SE |
| Sami (Inari) (Finland) | smn-FI |
| Sami (Skolt) (Finland) | sms-FI |
| Somali | so |
| Somali (Djibouti) | so-DJ |
| Somali (Ethiopia) | so-ET |
| Somali (Kenya) | so-KE |
| Somali (Somalia) | so-SO |
| Albanian | sq |
| Albanian (Albania) | sq-AL |
| Serbian | sr |
| Serbian (Cyrillic) (Bosnia and Herzegovina) | sr-Cyrl-BA |
| Serbian (Cyrillic) (Serbia and Montenegro (Former)) | sr-Cyrl-CS |
| Serbian (Cyrillic) (Montenegro) | sr-Cyrl-ME |
| Serbian (Cyrillic) (Serbia) | sr-Cyrl-RS |
| Serbian (Latin) (Bosnia and Herzegovina) | sr-Latn-BA |
| Serbian (Latin) (Serbia and Montenegro (Former)) | sr-Latn-CS |
| Serbian (Latin) (Montenegro) | sr-Latn-ME |
| Serbian (Latin) (Serbia) | sr-Latn-RS |
| Swedish | sv |
| Swedish (Finland) | sv-FI |
| Swedish (Sweden) | sv-SE |
| Kiswahili | sw |
| Kiswahili (Kenya) | sw-KE |
| Syriac | syr |
| Syriac (Syria) | syr-SY |
| Tamil | ta |
| Tamil (India) | ta-IN |
| Telugu | te |
| Telugu (India) | te-IN |
| Tajik (Cyrillic) (Tajikistan) | tg-Cyrl-TJ |
| Thai | th |
| Thai (Thailand) | th-TH |
| Turkmen (Turkmenistan) | tk-TM |
| Setswana (South Africa) | tn-ZA |
| Turkish | tr |
| Turkish (Turkey) | tr-TR |
| Tatar | tt |
| Tatar (Russia) | tt-RU |
| Tamazight (Latin) (Algeria) | tzm-Latn-DZ |
| Uyghur (People's Republic of China) | ug-CN |
| Ukrainian | uk |
| Ukrainian (Ukraine) | uk-UA |
| Urdu | ur |
| Urdu (Islamic Republic of Pakistan) | ur-PK |
| Uzbek | uz |
| Uzbek (Cyrillic) (Uzbekistan) | uz-Cyrl-UZ |
| Uzbek (Latin) (Uzbekistan) | uz-Latn-UZ |
| Vietnamese | vi |
| Vietnamese (Vietnam) | vi-VN |
| Wolof (Senegal) | wo-SN |
| isiXhosa (South Africa) | xh-ZA |
| Yoruba (Nigeria) | yo-NG |
| Chinese (Simplified) | zh-Hans |
| Chinese (Traditional) | zh-Hant |
| Chinese (People's Republic of China) | zh-CN |
| Chinese (Hong Kong S.A.R.) | zh-HK |
| Chinese (Macao S.A.R.) | zh-MO |
| Chinese (Singapore) | zh-SG |
| Chinese (Taiwan) | zh-TW |
| isiZulu (South Africa) | zu-ZA |

