Data Warehouses: Getting Started
PremiumThis feature is available on our Premium and Enterprise plans.Our data warehouse integrations let you send Customer.io data about messages, people, metrics, etc to your data warehouse by way of an Amazon S3 or Google Cloud Project (GCP) storage bucket. From there, you can ingest the data to your warehouse.
You can find our data warehouse integrations by going to Data & Integrations > Integrations and selecting the Databases option. From here, you can select your data warehouse or storage bucket. If your data warehouse appears twice in this list, pick the Data out integration. Check out the specific documentation for your data warehouse for help setting up your integration.
How it works
This integration exports individual parquet files for Deliveries, Metrics, Subjects, Outputs, Content, People, and Attributes to your storage bucket. Each parquet file contains data that changed since the last export.
Once the parquet files are in your storage bucket, you can import them into data platforms like Fivetran or data warehouses like Redshift, BigQuery, and Snowflake.
Note that this integration only publishes parquet files to your storage bucket. You must set your data warehouse to ingest this data. There are many approaches to ingesting data, but it typically requires a COPY command to load the parquet files from your bucket. After you load parquet files, you should set them to expire to delete them automatically.
We attempt to export parquet files every 15 minutes, though actual sync intervals and processing times may vary. When syncing large data sets, or Customer.io experiences a high volume of concurrent sync operations, it can take up to several hours to process and export data. This feature is not intended to sync data in real time.
before next sync end
Your initial sync includes historical data
During the first sync, you’ll receive a history of your Deliveries, Metrics, Subjects, and Outputs data. However, People who have been deleted or suppressed before the first sync are not included in the People file export and the historical data in the other export files is anonymized for the deleted and suppressed People.
The initial export vs incremental exports
Your initial sync is a set of files containing historical data to represent your workspace’s current state. Subsequent sync files contain changesets.
- Metrics: The initial metrics sync is broken up into files with two sequence numbers, as follows.
<name>_v4_<workspace_id>_<sequence1>_<sequence2>. - Attributes: The initial Attributes sync includes a list of profiles and their current attributes. Subsequent files will only contain attribute changes, with one change per row.
When you set up your sync, you can choose the parquet files that you want to export to your storage bucket. If you temporarily disable a file, and then turn it back on, the next parquet file will contain the changeset between when you disabled the file and when you enabled it.
already enabled?} c-->|yes|d[send changes since last sync] c-->|no|e{was the file
ever enabled?} e-->|yes|f[send changeset since
file was disabled] e-->|no|g[send all history]
For example, let’s say you’ve enabled the Attributes export. We will attempt to sync your data to your storage bucket every 15 minutes:
- 12:00pm We sync your Attributes Schema for the first time. This includes a list of profiles and their current attributes.
- 12:05pm User1’s email is updated to company-email@example.com.
- 12:10pm User1’s email is updated to personal-email@example.com.
- 12:15 We sync your data again. In this export, you would only see attribute changes, with one change per row. User1 would have one row dedicated to his email changing.
How do I get data into my data warehouse?
There are many approaches to ingesting data from your storage bucket, but here’s an example moving data from from a Google Cloud Storage bucket to Google BigQuery.
- Implement a Cloud Function to automatically import the parquet files from your GCS bucket to a BigQuery table.
- Set an expiration on the parquet files so they’re automatically deleted.
Below is a screenshot of an example Cloud Function. You can download sample code for this cloud function—based on our v3 schema—below here:
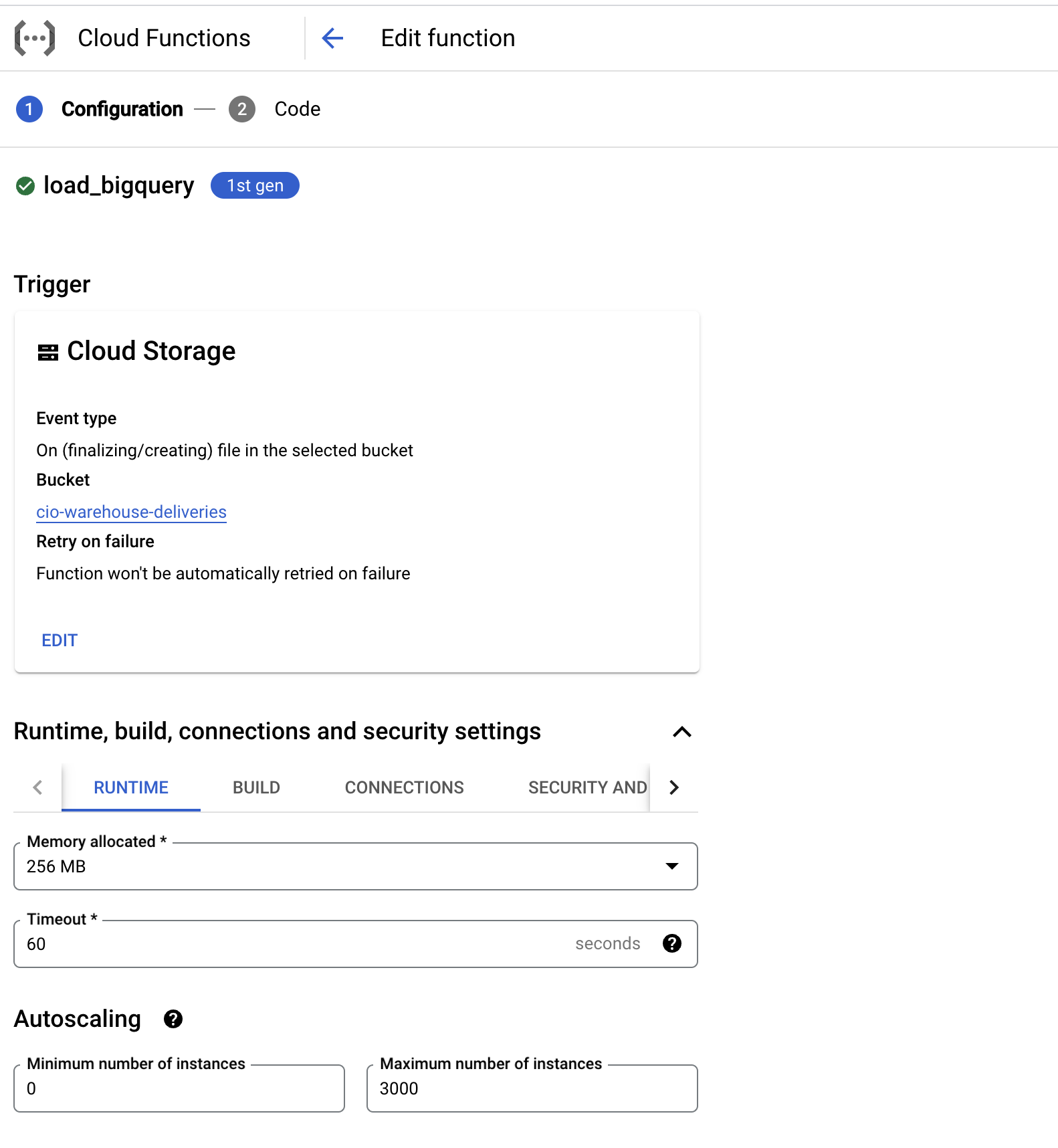
Our sample does not work for v4 schema, and it won’t work out of the box if you use a subfolder in the sync option. Make sure you review the code and making appropriate modifications to fit your use case.
Exported parquet files
This section describes the different kinds of files you can export from our Database-out integrations. Many schemas include an internal_customer_id—this is the cio_idAn identifier for a person that is automatically generated by Customer.io and cannot be changed. This identifier provides a complete, unbroken record of a person across changes to their other identifiers (id, email, etc).. You can use it to resolve a person associated with a subject, delivery, etc.
Deliveries schema
Deliveries are individual email, in-app, push, SMS, slack, and webhook records sent from your workspace. The first deliveries export file includes baseline historical data. Subsequent files contain rows for data that changed since the last export.
| Field Name | Primary Key | Foreign Key | Description |
|---|---|---|---|
| workspace_id | INTEGER (Required). The ID of the Customer.io workspace associated with the delivery record. | ||
| delivery_id | ✅ | STRING (Required). The ID of the delivery record. | |
| internal_customer_id | People | STRING (Nullable). The cio_id of the person in question. Use the people parquet file to resolve this ID to an external customer_id or email address. | |
| subject_id | Subjects | STRING (Nullable). If the delivery was created as part of a Campaign or API Triggered Broadcast workflow, this is the ID for the path the person went through in the workflow. Note: This value refers to, and is the same as, the subject_name in the subjects table. | |
| event_id | Subjects | STRING (Nullable). If the delivery was created as part of an event-triggered Campaign, this is the ID for the unique event that triggered the workflow. Note that this is a foreign key for the subjects table, and not the metrics table. | |
| delivery_type | STRING (Required). The type of delivery: email, push, in-app, sms, slack, or webhook. | ||
| campaign_id | INTEGER (Nullable). If the delivery was created as part of a Campaign or API Triggered Broadcast workflow, this is the ID for the Campaign or API Triggered Broadcast. | ||
| action_id | INTEGER (Nullable). If the delivery was created as part of a Campaign or API Triggered Broadcast workflow, this is the ID for the unique workflow item that caused the delivery to be created. | ||
| newsletter_id | INTEGER (Nullable). If the delivery was created as part of a Newsletter, this is the unique ID of that Newsletter. | ||
| content_id | INTEGER (Nullable). If the delivery was created as part of a Newsletter split test, this is the unique ID of the Newsletter variant. | ||
| trigger_id | INTEGER (Nullable). If the delivery was created as part of an API Triggered Broadcast, this is the unique trigger ID associated with the API call that triggered the broadcast. | ||
| created_at | TIMESTAMP (Required). The timestamp the delivery was created at. | ||
| transactional_message_id | INTEGER (Nullable). If the delivery occurred as a part of a transactional message, this is the unique identifier for the API call that triggered the message. | ||
| seq_num | INTEGER (Required) A monotonically increasing number indicating relative recency for each record: the larger the number, the more recent the record. |
Delivery Content schema
The delivery_content schema represents message contents; each row corresponds to an individual delivery. Use the delivery_id to find more information about the contents of a message, or the recipient to find information about the person who received the message.
If your delivery was produced from a campaign, it’ll include campaign and action IDs, and the newsletter and content IDs will be null. If your delivery came from a newsletter, the row will include newsletter and content IDs, and the campaign and action IDs will be null.
Delivery content might lag behind other tables by 15-30 minutes (or roughly 1 sync operation). We package delivery contents on a 15 minute interval, and can export to your data warehouse up to every 15 minutes. If these operations don’t line up, we might occasionally export delivery_content after other tables.
Delivery content can be a very large data set
Workspaces that have sent many messages may have hundreds or thousands of GB of data.
Delivery content is available in v4 or later
The delivery_content schema is new in v4. You need to update your data warehouse schemas to take advantage of the update and see Delivery Content, Subjects, and Outputs.
| Field Name | Primary Key | Foreign Key | Description |
|---|---|---|---|
| delivery_id | ✅ | Deliveries | STRING (Required). The ID of that delivery associated with the message content. |
| workspace_id | INTEGER (Required). The ID of the Customer.io workspace associated with the output record. | ||
| type | STRING (Required). The delivery type—one of email, sms, push, in-app, or webhook. | ||
| campaign_id | INTEGER (Nullable). The ID for the campaign that produced the content (if applicable). | ||
| action_id | INTEGER (Nullable). The ID for the campaign workflow item that produced the content. | newsletter_id | INTEGER (Nullable). The ID for the newsletter that produced the content. | content_id | INTEGER (Nullable). The ID for the Newsletter A/B test item that produced the content, 0 indexed. If your Newsletter did not include an A/B test, this value is 0. | from | STRING (Nullable). The from address for an email, if the content represents an email. | reply_to | STRING (Nullable). The Reply To address for an email, if the content is related to an email. |
| bcc | STRING (Nullable). The Blind Carbon Copy (BCC) address for an email, if the content is related to an email. | ||
| recipient | STRING (Required). The person who received the message, dependent on the type. For an email, this is an email address; for an SMS, it's a phone number; for a push notification, it's a device ID. | ||
| subject | STRING (Nullable). The subject line of the message, if applicable; required if the message is an email | body | STRING (Required). The body of the message, including all HTML markup for an email. |
| body_amp | STRING (Nullable). The HTML body of an email including any AMP-enabled JavaScript included in the message. | ||
| body_plain | STRING (Required). The plain text of your message. If the content type is email, this is the message text without HTML tags and AMP content. | ||
| preheader | STRING (Nullable). "Also known as "preview text", this is the block block of text that users see next to, or underneath, the subject line in their inbox. | ||
| url | STRING (Nullable). If the delivery is an outgoing webhook, this is the URL of the webhook. | ||
| method | STRING (Nullable). If the delivery is an outgoing webhook, this is the HTTP method used—POST, PUT, GET, etc. | ||
| headers | STRING (Nullable). If the delivery is an outgoing webhook, these are the headers included with the webhook. |
Metrics schema
Metrics exports detail events relating to deliveries (e.g. messages sent, opened, etc). Your initial metrics export contains baseline historical data, broken up into files with two sequence numbers, as follows:
<name>_v4_<workspace_id>_<sequence1>_sequence2>.
Subsequent files contain rows for data that changed since the last export.
| Field Name | Primary Key | Foreign Key | Description |
|---|---|---|---|
| event_id | ✅ | STRING (Required). The unique ID of the metric event. This can be useful for deduplicating purposes. | |
| workspace_id | INTEGER (Required). The ID of the Customer.io workspace associated with the metric record. | ||
| delivery_id | Deliveries | STRING (Required). The ID of the delivery record. | |
| metric | STRING (Required). The type of metric (e.g. sent, delivered, opened, clicked). | ||
| reason | STRING (Nullable). For certain metrics (e.g. attempted), the reason behind the action. | ||
| link_id | INTEGER (Nullable). For "clicked" metrics, the unique ID of the link being clicked. | ||
| link_url | STRING (Nullable). For "clicked" metrics, the URL of the clicked link. (Truncated to 1000 bytes.) | ||
| created_at | TIMESTAMP (Required). The timestamp the metric was created at. | ||
| seq_num | INTEGER (Required) A monotonically increasing number indicating relative recency for each record: the larger the number, the more recent the record. |
Subjects schema
Subjects are the unique workflow journeys that people take through Campaigns and API Triggered Broadcasts. The first subjects export file includes baseline historical data. Subsequent files contain rows for data that changed since the last export.
Upgrade to v4 to use subjects and outputs
We’ve made some minor changes to subjects and outputs a part of our v4 release. If you’re using a previous schema version, we disabled your subjects and outputs on October 31st, 2022. You need to upgrade to schema version 4, to continue syncing outputs and subjects data.
| Field Name | Primary Key | Foreign Key | Description |
|---|---|---|---|
| workspace_id | INTEGER (Required). The ID of the Customer.io workspace associated with the subject record. | ||
| subject_name | ✅ | STRING (Required). A unique ID for the path a person took through a campaign or broadcast workflow. | |
| internal_customer_id | People | STRING (Nullable). The cio_id of the person in question. Use the people parquet file to resolve this ID to an external customer_id or email address. | |
| campaign_type | STRING (Required). The type of Campaign (segment, event, or triggered_broadcast) | ||
| campaign_id | INTEGER (Required). The ID of the Campaign or API Triggered Broadcast. | ||
| event_id | Metrics | STRING (Nullable). The ID for the unique event that triggered the workflow. | |
| trigger_id | INTEGER (Optional). If the delivery was created as part of an API Triggered Broadcast, this is the unique trigger ID associated with the API call that triggered the broadcast. | ||
| started_campaign_at | TIMESTAMP (Required). The timestamp when the person first matched the campaign trigger. For event-triggered campaigns, this is the timestamp of the trigger event. For segment-triggered campaigns, this is the time the user entered the segment. | ||
| created_at | TIMESTAMP (Required). The timestamp the subject was created at. | ||
| seq_num | INTEGER (Required) A monotonically increasing number indicating relative recency for each record: the larger the number, the more recent the record. |
Outputs schema
Outputs are the unique steps within each workflow journey. The first outputs file includes historical data. Subsequent files contain rows for data that changed since the last export.
Upgrade to v4 to use subjects and outputs
We’ve made some minor changes to subjects and outputs a part of our v4 release. If you’re using a previous schema version, we disabled your subjects and outputs on October 31st, 2022. You need to upgrade to schema version 4, to continue syncing outputs and subjects data.
| Field Name | Primary Key | Foreign Key | Description |
|---|---|---|---|
| workspace_id | INTEGER (Required). The ID of the Customer.io workspace associated with the output record. | ||
| output_id | ✅ | STRING (Required). The ID for the step of the unique path a person went through in a Campaign or API Triggered Broadcast workflow. | |
| subject_name | Subjects | STRING (Required). A secondary unique ID for the path a person took through a campaign or broadcast workflow. | |
| output_type | STRING (Required). The type of step a person went through in a Campaign or API Triggered Broadcast workflow. Note that the "delay" output_type covers many use cases: a Time Delay or Time Window workflow item, a "grace period", or a Date-based campaign trigger. | ||
| action_id | INTEGER (Required). The ID for the unique workflow item associated with the output. | ||
| explanation | STRING (Required). The explanation for the output. | ||
| delivery_id | Deliveries | STRING (Nullable). If a delivery resulted from this step of the workflow, this is the ID of that delivery. | |
| draft | BOOLEAN (Nullable). If a delivery resulted from this step of the workflow, this indicates whether the delivery was created as a draft. | ||
| link_tracked | BOOLEAN (Nullable). If a delivery resulted from this step of the workflow, this indicates whether links within the delivery are configured for tracking. | ||
| split_test_index | INTEGER (Nullable). If the step of the workflow was a Split Test, this indicates the variant of the Split Test. | ||
| delay_ends_at | TIMESTAMP (Nullable). If the step of the workflow involves a delay, this is the timestamp for when the delay will end. | ||
| branch_index | INTEGER (Nullable). If the step of the workflow was a T/F Branch, a Multi-Split Branch, or a Random Cohort Branch, this indicates the branch that was followed. | ||
| manual_segment_id | INTEGER (Nullable). If the step of the workflow was a Manual Segment Update, this is the ID of the Manual Segment involved. | ||
| add_to_manual_segment | BOOLEAN (Nullable). If the step of the workflow was a Manual Segment Update, this indicates whether a person was added or removed from the Manual Segment involved. | ||
| created_at | TIMESTAMP (Required). The timestamp the output was created at. | ||
| seq_num | INTEGER (Required) A monotonically increasing number indicating relative recency for each record: the larger the number, the more recent the record. |
People schema
The first People export file includes a list of current people at the time of your first sync (deleted or suppressed people are not included in the first file). Subsequent exports include people who were created, deleted, or suppressed since the last export.
People exports come in two different files:
people_v4_<env>_<seq>.parquet: Contains new people.people_v4_chngs_<env>_<seq>.parquet: Contains changes to people since the previous sync.
These files have an identical structure and a part of the same data set. You should import them to the same table.
| Field Name | Primary Key | Foreign Key | Description |
|---|---|---|---|
| workspace_id | INTEGER (Required). The ID of the Customer.io workspace associated with the person. | ||
| customer_id | STRING (Required). The ID of the person in question. This will match the ID you see in the Customer.io UI. | ||
| internal_customer_id | ✅ | STRING (Required). The cio_id of the person in question. Use the people parquet file to resolve this ID to an external customer_id or email address. | |
| deleted | BOOLEAN (Nullable). This indicates whether the person has been deleted. | ||
| suppressed | BOOLEAN (Nullable). This indicates whether the person has been suppressed. | ||
| created_at | TIMESTAMP (Required). The timestamp of the most recent change to the id attribute (this is typically when the id is first set). If the id attribute doesn’t exist (the person is identified only by their email address), this value is the last time the profile changed. | ||
| updated_at | TIMESTAMP (Required) The date-time when a person was updated. Use the most recent updated_at value for a customer_id to disambiguate between multiple records. | ||
| email_addr | STRING (Optional) The email address of the person. For workspaces using email as a unique identifier, this value may be the same as the customer_id. |
Attributes schema
Attribute exports represent changes to people (by way of their attribute values) over time. The initial Attributes export includes a list of profiles and their current attributes. Subsequent files contain attribute changes, with one change per row.
| Field Name | Primary Key | Foreign Key | Description |
|---|---|---|---|
| workspace_id | INTEGER (Required). The ID of the Customer.io workspace associated with the person. | ||
| internal_customer_id | ✅ | STRING (Required). The cio_id of the person in question. Use the people parquet file to resolve this ID to an external customer_id or email address. | |
| attribute_name | STRING (Required). The attribute that was updated. | ||
| attribute_value | STRING (Required). The new value of the attribute. | ||
| timestamp | TIMESTAMP (Required). The timestamp of the attribute update. |
Changelog
v4
If you’re on a prior schema, your Objects and Subjects tables were disabled on October 31, 2022. You’ll need to upgrade to continue receiving subjects and outputs.
Version 4 includes the following changes from v3:
- The Subjects and Outputs tables have been disabled for previous versions. You must update to v4 to use Subjects and Outputs.
- Added a Delivery Content table, similar to the Deliveries table but this new table includes the actual message content for each delivery. You can associate content with a delivery by
delivery_id. - The Outputs schema now includes a new
subject_namecolumn. This is the same column from the Subjects table. - Removed
subject_idfrom the Outputs table.
Upgrade to v4
- In your Customer.io workspace, go to Data & Integrations > Integrations, and click your data warehouse integration.
- Click Upgrade Sync. We’ll automatically disable the Subjects and Outputs schemas, so you can update your database.
- In your database, add a string-type
subject_namecolumn to the Outputs table. - Query the Subjects table to populate the new
outputs.subject_namecolumn. - Drop the
subject_idcolumn from the Subjects and Outputs tables in your database. - (Optional) Create a Delivery Content table based on the new
delivery_contentschema - Return to Customer.io and re-enable the Subjects, Outputs, and/or Delivery Content schemas.
v3
Version 3 includes the following changes from v2:
- A
seq_numcolumn in the Deliveries, Subjects, Outputs, and Metrics tables. This is a constantly increasing value, where a larger value indicates a more current record. - People tables now contain record updates, rather than only the record as first created. For example, we produce a new record if you change a person’s email, delete them, or suppress them.
- The People table now has an
updated_atcolumn. Because many data warehouses don’t replace rows when adding duplicate primary keys, you can select the most recentupdated_atvalue for each profile. - The People table now contains an
email_addrcolumn.
v2
Data warehouse sync v2 includes the following changes from v1:
- Support for transactional messages (as
transactional_message_id) in the Deliveries schema. - A fix for an issue that caused missing rows in Subjects and Outputs data. As a result of this bug, data warehouse v1 no longer supports Subjects or Outputs data.
If you used our initial data warehouse release, we recommend updating to the v2 implementation. However, you can continue using our original data warehouse sync feature if you don’t use:
- Subjects and/or Outputs data
- Transactional messages
Frequently asked questions
How are exported parquet files organized?
Each parquet file is named <name>_v<x>_<workspace_id>_<sequence>.
- <name> is either deliveries, metrics, subjects, outputs, or people.
- v
Indicates the schema version. The current version is v2; v1 schemas do not have a version indicator and are deprecated. - <workspace_id> refers to the Customer.io workspace whose data is included.
- <sequence> is an ever-increasing value over time.
Initial metrics sync file names
Your initial metrics sync is broken up into files that indicate a starting and ending sequence, to help you order things appropriately, for example:
<name>_v<x>_<workspace_id>_<sequence_pt1>_<sequence_pt2>
How do you handle export failures?
If we experience an internal failure, we monitor and repair it promptly. If there’s an external failure such as a networking problem, we retry the export. If there’s an issue with bucket access, we’ll reach out to you with details.
In each retry case, the next export will contain all data since the prior export. No data will be lost.
How should I import data from my bucket to my data warehouse?
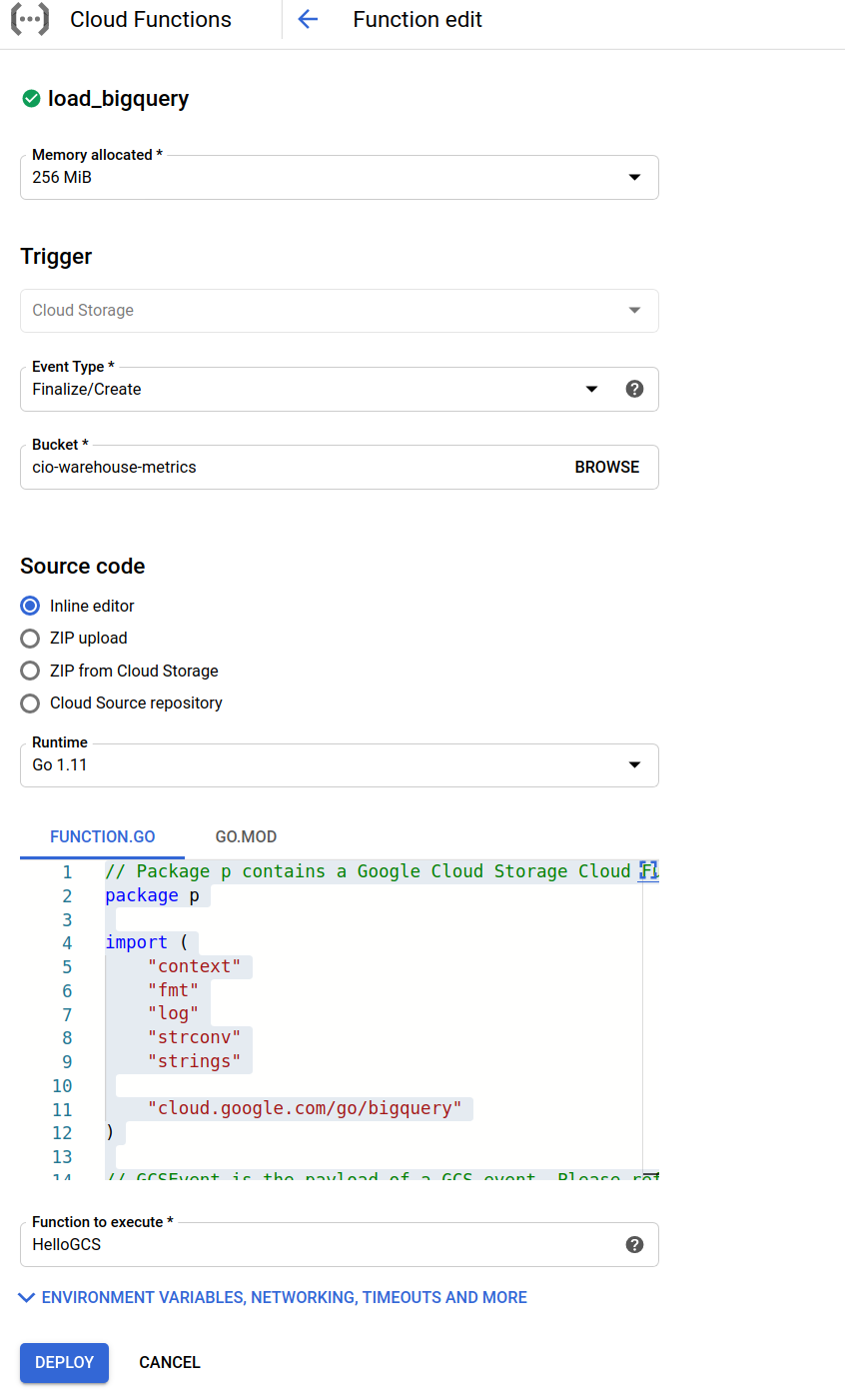
There are many approaches to this, but here’s one example we’ve seen work for moving data from a GCS bucket to BigQuery.
- Implement a Cloud Function to automatically import the parquet files from your GCS bucket to a BigQuery table.
- Set an expiration on the parquet files so they get automatically deleted.
Below is a screenshot of an example Cloud Function. You can download sample code for this cloud function—based on our v4 schemas—below here:
How can I get information about a campaign, workflow action, or message that’s not included in the export?
With the data in our export, it’s possible to query our API to pull any extra information you need.
For example, calling https://api.customer.io/v1/campaigns/:id with the id of the campaign from a subject record will give you details about the campaign.
Check out our full API docs here.
How do I get all of the current attributes for a profile? On setup, the initial Attributes export will include a list of profiles and their current attributes. Subsequent files will only contain attribute changes, with one change per row. In order to get the most recent attributes for a particular profile, you’ll need to use the timestamp value to query for the latest.
An example query for Snowflake would be:
select internal_customer_id, attribute_name, attribute_value
from (select internal_customer_id, attribute_name, attribute_value, row_number() over (partition by internal_customer_id,attribute_name order by timestamp desc) RNO from attributes)
where rno=1 and internal_customer_id='xxxxxxxxxxx';

