Understanding Reverse ETL Sources
How it works
Our data warehouse and database sources operate as “reverse ETL” (Extract, Transform, Load) integrations: they extract data from a data warehouse so you can take advantage of your data in your third party destinations. These sources help you leverage your big data storage in destinations where you can act on it. For example, you might write a query representing track events so you can sync records from Snowflake to Mixpanel.
When you set up a data warehouse or database source, you’ll set up one or more syncs. This is the kind of source call you want to transform your data into (like track, identify, etc) and the query that returns the data you want to send to destinations. Each row returned from the query represents a source call.
You’ll have to create a sync for each kind of source call you want to send to your destinations. We run your query on an interval, and expose a last_sync_time value that you can use to make sure that you only sync source data that changed since the previous sync interval.
Add a reverse ETL or database source
Before you add a source, we suggest that you set up a service account or create a user account specifically for Customer.io with read-only access to the tables you want to sync. This helps you ensure the security of your data, and gives you a way to revoke access if you need to.
Your database must allow connections from 34.29.50.4 or 34.22.168.136 if your account is in our EU region. If our IP address is blocked, we won’t be able to connect to your database.
- Go to the tab and click Sources.
- Click Add Source and pick your Data Warehouse or Database source.
- Give your database a name and connect your database to Customer.io
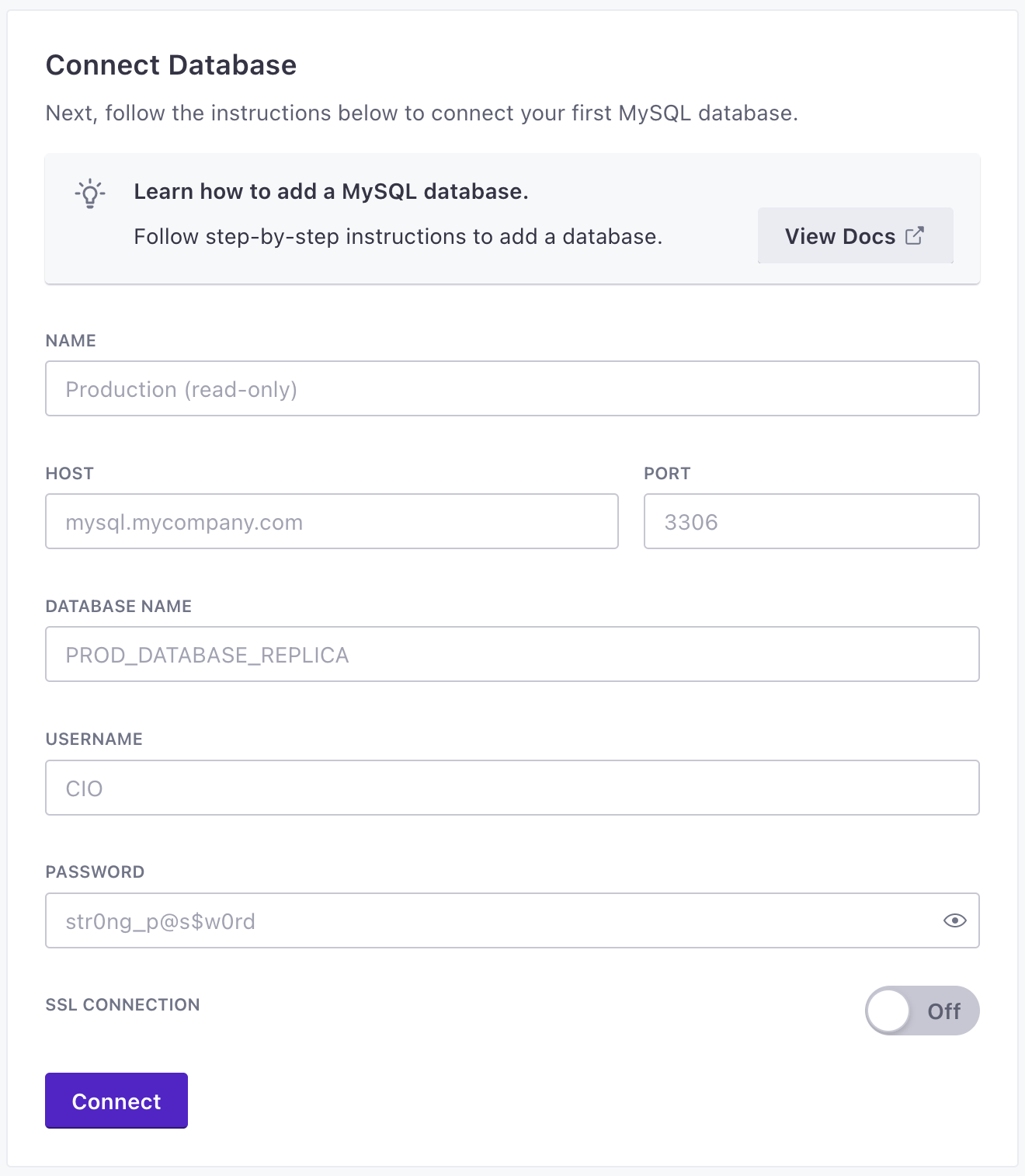
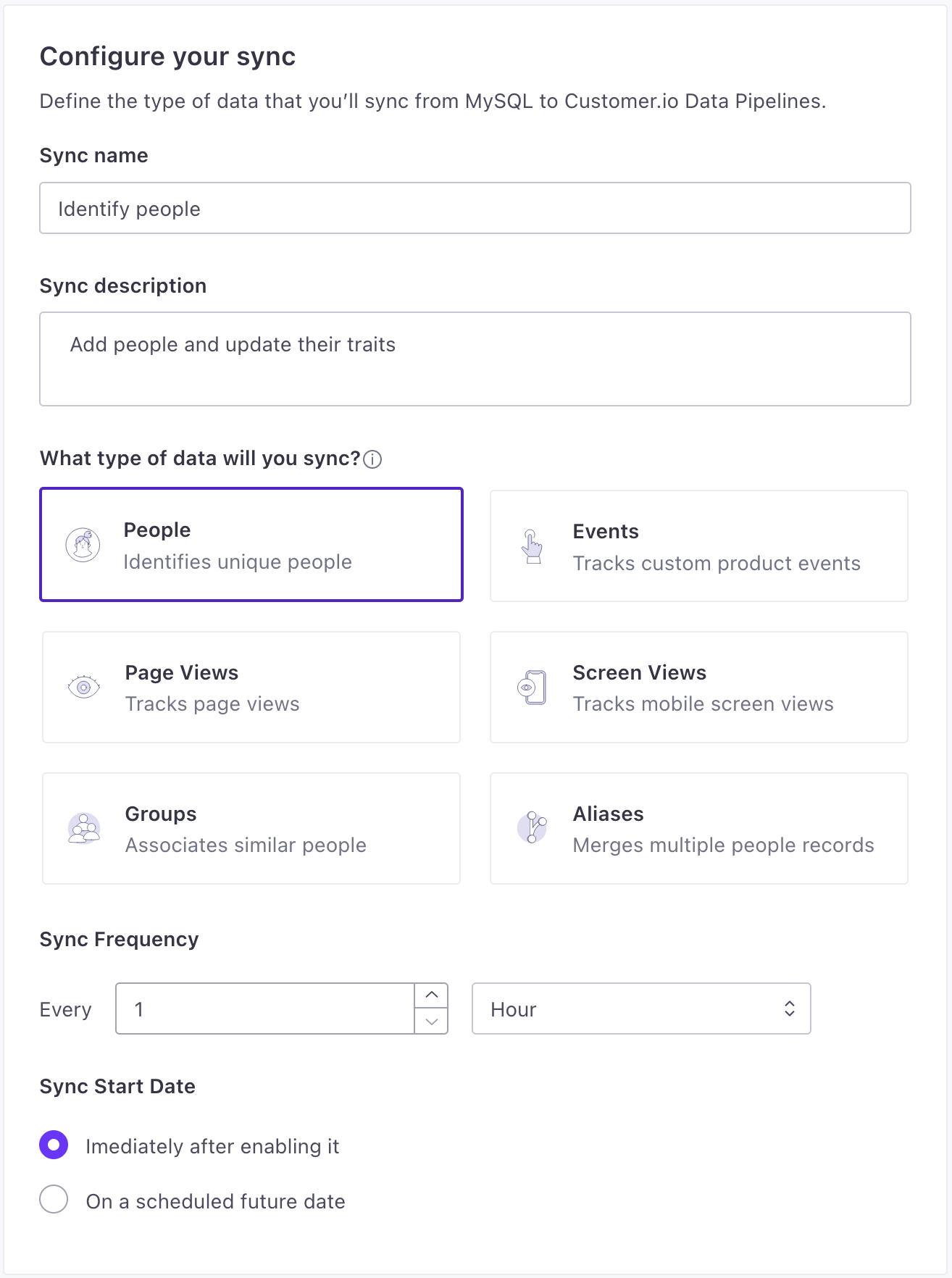
- Set up a Sync. A sync is the type of source data (
identify,track, etc) you want to import from your database and click Next: Define Query. You can set up syncs for each type of data you want to import for your source.- Provide a Name and Description for the sync. This helps you understand the sync at a glance when you look at your source Overview later.
- Select the type of data you want to import.
- Set the Sync Frequency, indicating how often you want to query your database for new data. You should set the frequency such that sync operations don’t overlap. Learn more about sync frequency.
- Select when you want to start the sync: whether you want to begin importing data immediately, or schedule the sync to start at a later date.
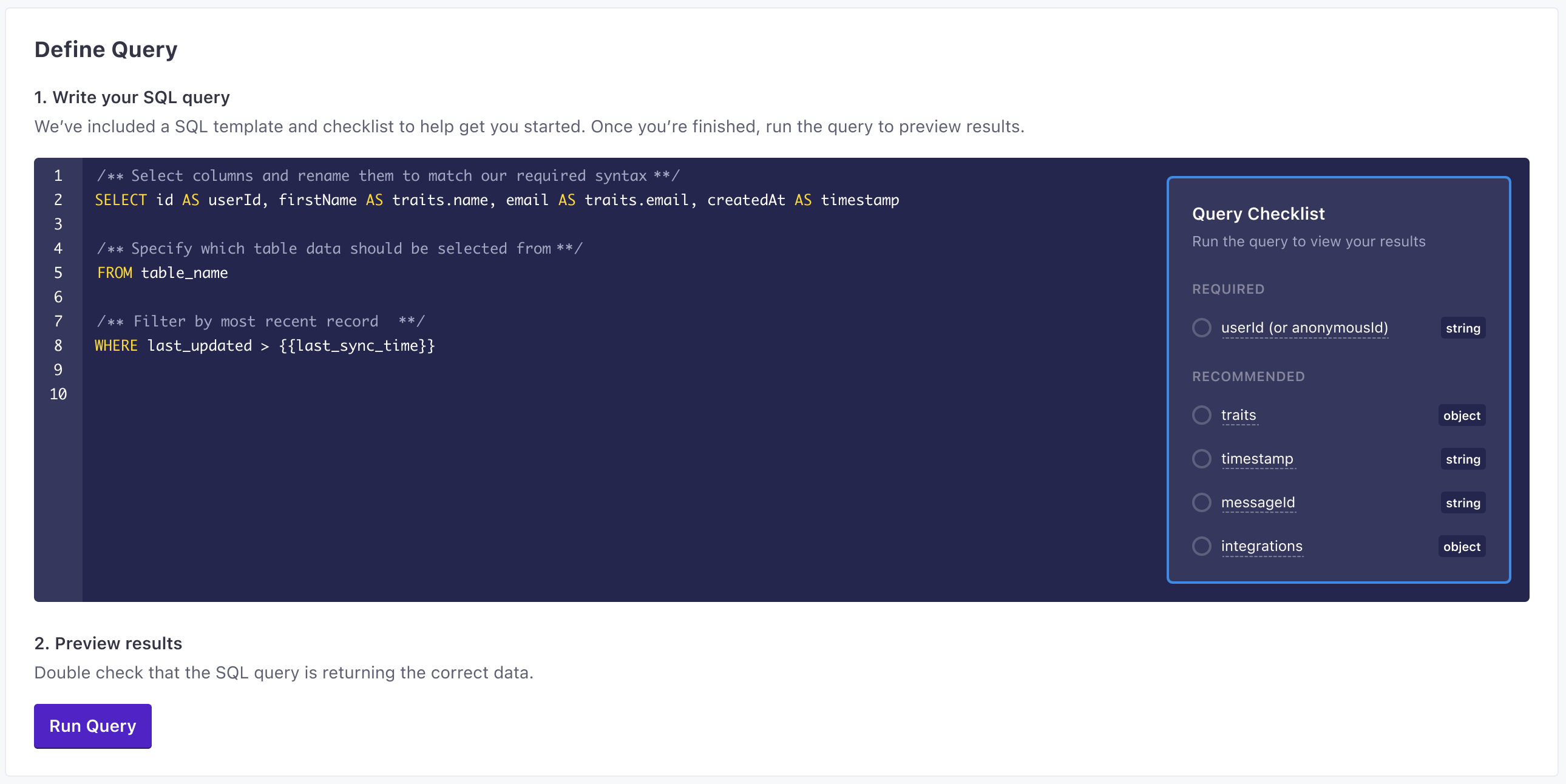
- Enter the query that selects the data you want to import. Click Run Query to preview results and make sure that your query selects the right information.
- Click Enable to enable your sync.
Now you can connect your source to one or more destinations and calls from your source and sync will flow to your destinations.
Add additional sync models
A sync defines the type of source calls you want to make and the query that returns the data you want to capture on every interval. Each row returned from the query represents a source call.
After you set up your destination, you can add subsequent syncs to extract and transform data into additional source calls by going to the Sync tab for your source and clicking Add sync.
Last sync time: sync only the records you want
We expose a last_sync_time variable that you should use in your query to sync only the records that have changed since the last sync. This helps you avoid syncing the same records over and over again—which can cause each query to take longer, risk sending duplicate information to your destinations, and increase your bill!
We strongly recommend that you index a column in your database representing the date-time each row was last-updated. When you write your query, you should add a WHERE clause comparing your “last updated” column to the {{last_sync_time}}.
The last sync time is a Unix timestamp representing the date-time when the previous sync started. The first time you sync, {{last_sync_time}} will be 0, so you’ll sync all records. After that, you’ll only sync records that have changed since the last sync.
SELECT id AS userId, email, first_name, created AS created_at
FROM my_people
WHERE UNIX_TIMESTAMP(last_updated) > {{last_sync_time}}Reserved properties and traits
We automatically treat values that aren’t reserved by our source calls as traits or event properties depending on the type of call you send, so you don’t have to force your query to return data exactly in the shape of our source calls. For example, if you want to set the email trait, you can return user.email AS email.
For identify or group data, any property other than the following goes in the traits object: userId, anonymousId, groupId, integrations, messageId, timestamp, context.
For track, page, and screen data, any property other than the following goes in the properties object: userId, anonymousId, event, integrations, messageId, timestamp, context.
These fields correspond to the common fields that we reserve in each source call, and extend to children of these reserved fields. For example, context.ip is also reserved. Learn more about common fields in source calls.
Sync Frequency
You can sync data as often as every minute. However, we recommend that you set your sync frequency such that sync operations don’t overlap. If you schedule syncs such that a sync operation is scheduled to start while the previous operation is still we’ll skip the next sync operation.
Enable and disable syncs
In your source, you can go into the Syncs tab to enable and disable syncs. You can also delete syncs from this tab.
When you disable a sync, we stop running the associated query and sending the type of data to your various destinations. We don’t delete the sync, so you can re-enable it later.
When you enable a sync, we’ll resume the sync. The next sync interval will send all data that has changed since the last sync.

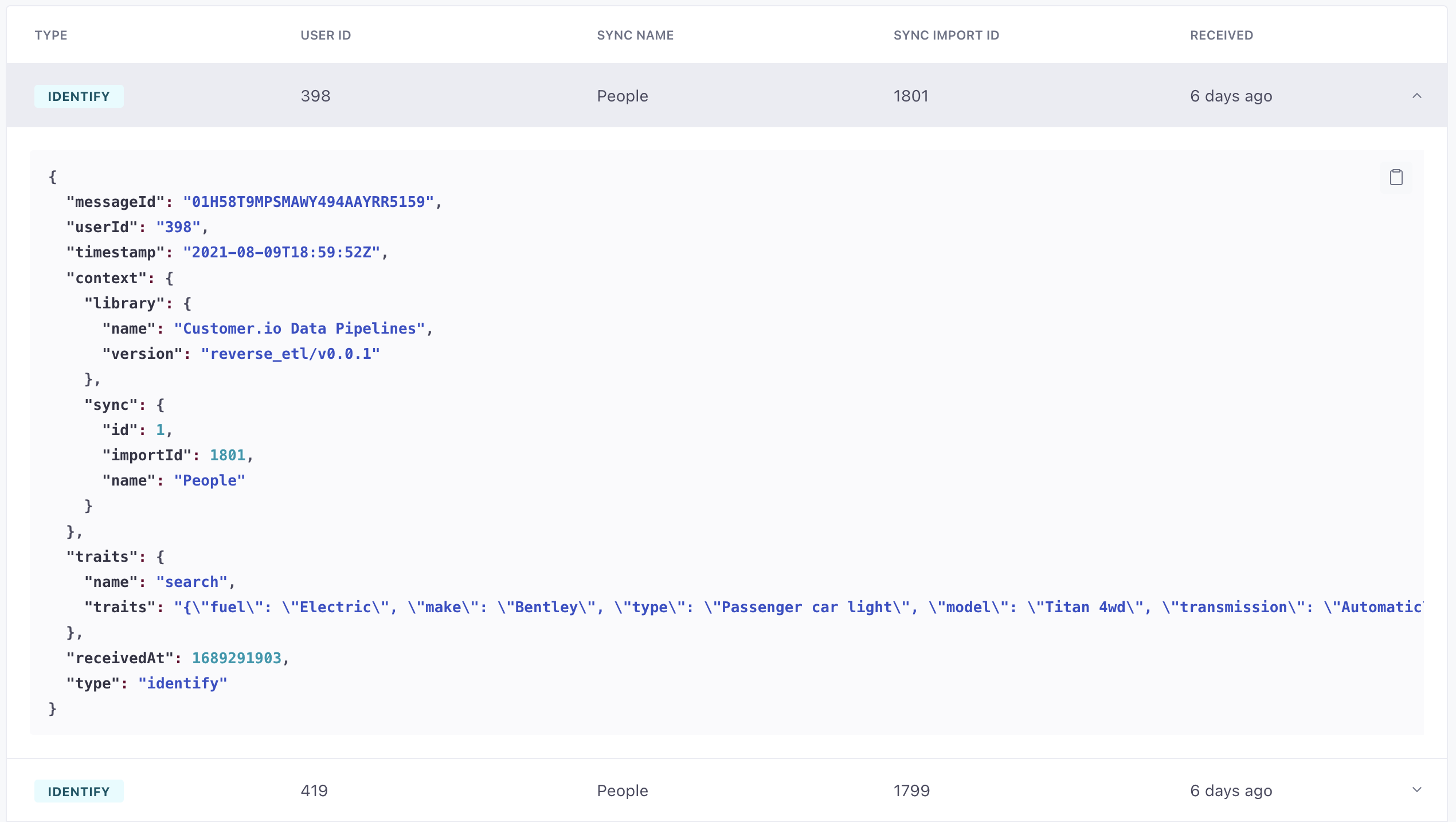
Errors and sync history
In the Imports tab for your source, we display a row for each sync interval showing the number of successful and unsuccessful rows—where each row represents a source call. You can click a sync to see errors. Typically errors occur when a row is either missing data or contains data that doesn’t map to the appropriate source call type.
If a sync has errors, the row also includes a Download button, so you can download a list of errors.
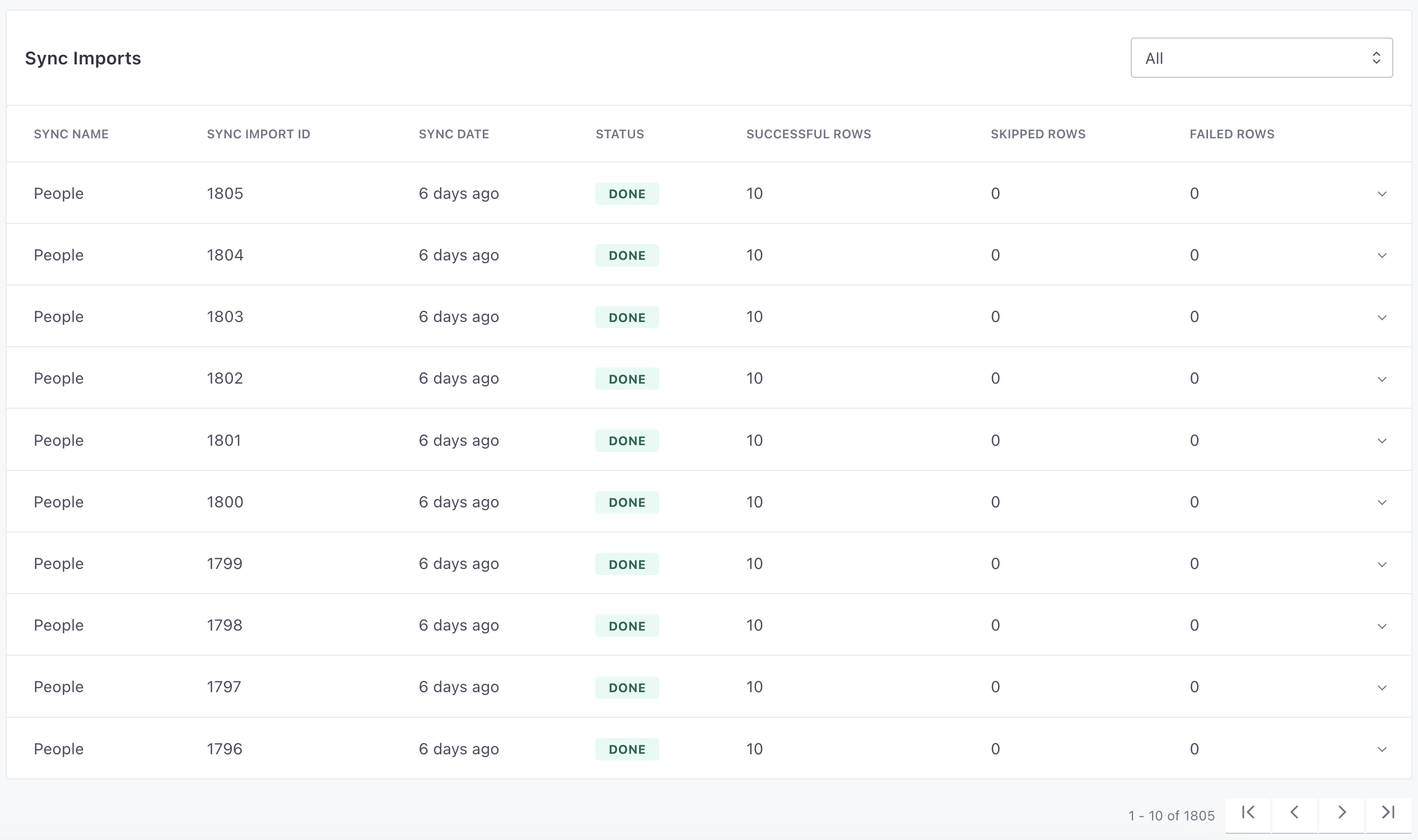
You can also go to the Syncs tab to see the status of your syncs, how often they run, and their last run time. You might use this tab to see if your syncs complete on time or if you need to decrease the frequency of syncs.
The Data In tab also shows successful source calls. You can use this to see exactly how your rows map to source calls.
Usage and billable API calls
We bill Data Pipeline usage based on the number of source calls you make. For database and reverse ETL integrations, each row returned from a sync/query represents a source call. If your database source contains three syncs, and each sync/query returns 100 rows, then you’ve made 300 billable source calls.
Sync query limits
| Name | Details | Limit |
|---|---|---|
| Maximum query length | The maximum length allowed for any query. | 131,072 characters |
userId column name length | The maximum length allowed for the userId column name. | 191 characters |
| timestamp column name length | The maximum length for the timestamp column name. | 191 characters |
| Sync frequency | The shortest possible duration between syncs. | 1 minutes |
Result limits
A sync cannot return more than 40 million records and 300 total columns.
| Name | Details | Limit |
|---|---|---|
| Record count | The maximum number of records a single sync will process. Note: This is the number of records extracted from the warehouse not the limit for the number of records loaded to the destination (for example, new/update/deleted). | 30 million records |
| Column count | The maximum number of columns a single sync will process. | 512 columns |
| Column name length | The maximum length of a record column. | 128 characters |
| Record JSON size | The maximum size for a record when converted to JSON (some of this limit is used by Customer.io). | 512 KiB |
| Column JSON size | The maximum size of any single column value. | 128 KiB |

